Parquet, Orc, Avro, CSV and JSON
We encounter data in many different formats. Some common examples are CSV, JSON, XML, Text, and Binary types. Every such format has a defined storage structure. CSV, JSON, and XML are all text-based formats. They describe the structure using text elements. For example, in a CSV file, the attributes are separated by a marker such as a comma, and end-of-line characters delimit records. Most data formats have some mechanism to define a schema, which helps understand the data type stored.
JSON and XML are the most popular data formats for transferring data among web-based services and clients. Text formats take more space to store and more processing power to parse but are easier to work with because regular text editing tools can inspect them. Binary file formats like Parquet and Avro provide a compact and efficient storage mechanism for faster search.
CSV
Comma-separated values (CSV) is a text file format used to store tabular data. A table is a set of rows with columns representing individual attributes of rows. In a CSV file, each data row has a separate line. For every row, the values of columns are separated by a comma. Values are stored as plain text. Here is a comma-separated CSV file that shows students' grades for different subjects they have taken. There is an optional header in the CSV file to label each column in the table.
CSV is a popular data format for storing small—to medium-scale data. Popular spreadsheet tools all support loading and saving CSV files. Even though using CSV files is widespread, it is not a standard. Different implementations can choose a host of methods to handle edge cases.
For example, since CSV files are comma-separated, a comma inside an attribute value must be handled in a particular way. An implementation can wrap values in quotation marks to handle commas inside a value. The same is true for line breaks within values. Some CSV implementations also support escape characters in handling such cases.
Other separators, such as tabs, spaces, and semicolons, are used in CSV files to separate the attributes. The specification RFC4180 was developed to standardize CSVs, but in practice, the implementations adhere to it loosely.
Since CSV is a text representation, it can take up more space than a compact binary format for the same data. To make this point, we can have a CSV file with two integer columns. Assume the row has the following two integers:
7428902344, 18234523
To write that row as plain text, each character must be translated into an encoded character value. If we assume ASCII format and allocate 1 byte for each character, our row will require 21 bytes (for each digit, line end character, delimiter, and space). Using a binary format, we only need 8 bytes to write the integer values, a reduction of more than half.
Additionally, we cannot look up a value in a CSV file without going through the previous lines since everything is text. In a structured binary file, the lookups can be much more efficient. Nevertheless, CSV files are widely used because humans can read them and because of the rich tools available to generate, load, visualize, and analyze them.
JSON
JSON stands for JavaScript Object Notation. It is the most popular data format used in web services. JSON is less verbose than XML, the standard for transferring data before JSON. JSON is primarily used with REST services on the Web, which is the dominant form of defining services.
A JSON document has two main structures: a collection of name-value pairs and an ordered list of values. Below is an example JSON document. A header is an object with a set of key-value pairs, while the body has only one value.
{
"header": {
"@contentType": "",
"to": "serviceX",
"from": "clientY"
},
"body": "Hello from client"
}Line-Delimited JSON
Line-delimited JSON is used to store records. With this format, each line contains a separate JSON object, as shown below. Different lines do not need to include the same type of record, but in practice, the same record is used in each line.
{"id": "12345","name":"Json", "text-format": true}
{"id": "67890","name":"XML", "text-format": true}
{"id": "67891","name":"Parquet", "text-format": false}These data formats are not designed to be queried at large scale. Imagine having a large number of JSON objects saved in the file system. We would need to parse these files to get helpful information, which is less efficient than going through a binary file.
Apache Parquet
Apache Parquest is a columnar data format for storing tabular data. It is a standard implemented in different languages for reading and writing. Parquet is the most popular data storage format supported by data processing systems in modern engines. It provides efficient data compression and encoding schemes to store extensive data sets cost-effectively.
We can break up a data table by storing the rows and columns in contiguous spaces. When storing rows, we refer to it as row-wise storage, and when storing columns, we call it column-wise storage or columnar storage. Parquet stores the data in the columnar format. Let us look at a simple example to understand the columnar option.
Assume we have a table with two columns and five rows of data. The first column holds a 32-bit integer value, and the second column holds a 64-bit integer value.
Assume we choose row-wise for binary representation. The figure below illustrates how this would look. Each row has 12 bytes, with a 4-byte and 8-byte integers. The values of each row are stored contiguously.

The figure below shows how it would be in a columnar format where each column is stored contiguously.

Both formats have advantages and disadvantages depending on the applications' access patterns and data manipulation requirements. For example, suppose an application must filter values based on those in a single column. In that case, column-based representation can be more efficient because we only need to traverse one column stored sequentially in the disk.
On the other hand, if we are looking to read all the values of each row consecutively, row-based representation would be preferable. In practice, we will use multiple operations, some of which can be efficient with row-wise storage and others with column-wise storage. Because of this, data storage systems often choose one format and stick to it, while others provide options to switch between formats.
Parquet supports the following data types. Since it handles variable-length binary data, user-defined data can be stored as binary objects.
- Boolean (1 bit)
- 32-bit signed integer
- 64-bit signed integer
- 96-bit signed integer
- IEEE 32-bit floating-point values
- IEEE 64-bit floating-point values
- Variable length byte arrays
The figure below shows the structure of a Parquet file, which contains a header, data block, and a footer. The header has a magic number to mark the file as a parquet. The footer includes metadata about the file—the data block contains the actual data encoded in a binary format.

The data blocks are organized into a hierarchical structure, with the topmost being a set of row groups. A row group contains data from a set of adjacent rows. Each group is divided into column chunks for every column in the table. A column chunk is divided into pages, a logical unit for saving column data.
The footer contains metadata about the data and the file structure. Each row group has metadata associated with it in the form of column metadata. A row group contains metadata about each column it stores. The column metadata includes information on the data types and page pointers.
Since the metadata is written at the end, Parquet can write the files with a single pass. This is possible because we can write the data without needing to calculate the structure of the data section. As a result, metadata can be read at the end of the file with a minimal number of disk seeks.
Apache ORC
Apache ORC is a columnar data format primarily developed for the Apache Hive project. It is a predecessor to Parquet and is still widely used in projects related to the Hadoop ecosystem.
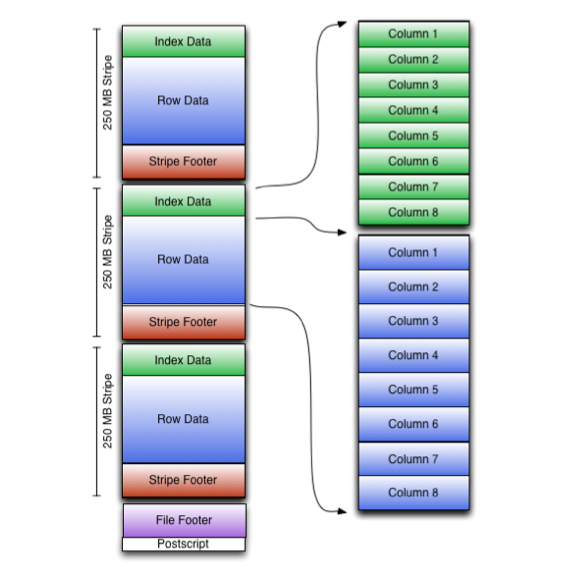
The ORC files store data in stripes, similar to row groups in Parquet. ORC supports lightweight indexes to data for efficient filtering and searching within the stripes. ORC supports the following data types.
- Integers-boolean, tinyint (8 bit), smallint (16 bit), int (32 bit), bigint (64 bit)
- Floating point — float, double
- String types — string, char, varchar
- Binary blobs
- Decimal type
- Date/time — timestamp, timestamp with local time zone, date
- Compound types — struct, list, map, union
ORC also includes metadata about the files and supports efficient filtering and searching of values.
Apache Avro
Apache Avro (or Avro) is a serialization library format that specifies how to pack data into byte buffers and definitions. Avro stores data in a row format, compared to Parquet and ORC’s columnar format. It has a schema to define the data types. Avro uses JSON objects to store the data definitions in a user-friendly format and binary format for the data. It supports the following data types that are similar to Parquet.
- Null having no value
- 32-bit signed integer
- 64-bit signed integer
- IEEE 32-bit floating-point values
- IEEE 64-bit floating-point values
- Unicode character sequence
- Variable-length bytes
The Avro schema allows us to code-generate objects and manipulate our data easily. It also has the option to work without code generation. Let's look at the Avro schema.
Avro Data Definitions (Schema)
Below, we can see a simple Avro schema that represents our message class.
{
"name": "Message",
"type": "record",
"namespace": "org.foundations",
"fields": [
{
"name": "header",
"type": {
"name": "header",
"type": "record",
"fields": [
{
"name": "@contentType",
"type": "string"
},
{
"name": "to",
"type": "string"
},
{
"name": "from",
"type": "string"
}
]
}
},
{
"name": "body",
"type": "string"
}
]
}We first set the name, type, and namespace of the object. Our object’s fully qualified name would be ‘org.foundations.Message’. Then, we specify the fields. We have a header field and a body field. The header is another record with three fields. The body field is of type string.
Code Generation
Once the schema is defined, we can generate code for our language of choice. The generated code allows us to work with our data objects efficiently. Code generation is excellent when we know the data types upfront. This would be the approach for custom solutions with specific data types. If we want to write a generic system that allows users to define types at runtime, code generation is no longer possible. In a scenario like that, we rely on Avro without code generation.
Without Code Generation
Avro Parsers can build and serialize Avro objects without code generation. This is important for applications with dynamic schemas only defined at runtime, as is the case for most data processing frameworks, where a user defines the data type at runtime.
Avro File
When serialized, an Avro file has the structure shown in Figure 2–7. It possesses a header with metadata about the data and a set of data blocks. The header includes the schema as a JSON object and the codec for packing the values into the byte buffers. Finally, the header has a 16-byte sync marker to indicate the end. Each data block contains a set of rows. It has an object count and size of total bytes for the rows (objects). The serialized objects are held in a contiguous space, followed by the 16-byte marker to indicate the end of the block. As with Parquet, Avro files are designed to work with block storage.

Schema Evolution
Data can change over time, and unstructured data is especially likely to change over time. Schema evolution is the term used to describe a situation in which files are written using one schema, but then we change the schema and use the new one with the older files. Schema evolution is something we need to plan and design carefully. We must keep the old schema the same and expect everything to work. Some rules and limitations define what changes are possible for Avro.
- We can add a new field with a default value.
- We can remove a field with a default value.
- We can change, add, or remove the doc attribute.
- We can change, add, or remove the order attribute.
- We can change the default value for a field.
- We can change a non-union type to a union that contains only the original type.
To change the schema like this, we must define the original schema fields susceptible to change with the above modification rules. For example, we must set default values to change a field.
Summary
This article described a few data formats used for storing data. Different file formats can be used depending on the use cases. Parquet is the most popular binary format now, and JSON and CSV are still widely used.











